 新入社員ブログ2022
新入社員ブログ2022 
今回は5つのテーマのうちの「5. 会社では習わないけどちょっと使えるコンピュータの知恵」についてご紹介いたします。
よくインターネットなどで入手したテキストファイルやメディアファイルの名前が文字化けしているということがよくあると思います。
例えばこのようなテキストが書かれたテキストファイルがあります。

このファイルを開く際に「UTF-8」という文字コードを指定して開くと上記のように正常に開けます。
次にこのファイルを「ANSI」という文字コードで指定して開くと。
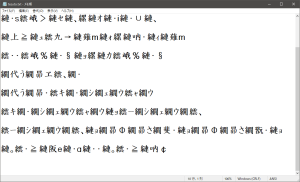
このように文字化けしてしまいます。
なぜ文字コードが違うと文字化けしてしまうのでしょうか。
文字コードとは
まず、文字コードとは何でしょうか。
文字コードはコンピュータ上で文字を扱う場合に使われる符号のことです。
たとえばアセンブラというプログラミング言語では「JIS X 0201」という規格の文字コードが使われています。
「A」という文字を出力するときは「#0041」という番号を16進数で入力しなければ表示できません。
あらかじめコンピュータ間で文字コードを決めておくと画像で文字を表現するよりも容量を軽くできるメリットがあります。なので文字コードが使われます。
文字コード規格の乱立
ここからは実話を簡略した作り話です。
アメリカは英文字と数字しか扱えない文字コード(以下英コード)を作りました。しかし日本人には不便なので日本語も扱えるように日本が独自に日コードという文字コードを開発しました。英コードでは#0001が「A」~#001Aが「Z」と定義しました。日コードでは#0001が「あ」~#0032が「ん」と定義しました。
次々と中国、韓国、ロシアなども自国の言語に対応させようと様々な文字コードを作りました。
という風に多言語対応するために規格が乱立していき文字コードがたくさんできてしまいました。
よく文字化けするシチュエーション
アメリカ人が英コードで「ABCDE」という記述をしたテキストを作り日本人に送りました。日本人が日コードでそのテキストを開くと「あいうえお」と表示されました。これが文字化けです。
文字化けしたときは
最初の例のように文字化けして表示されてしまったときは、文字コードを違うもので指定して開き直しましょう。
「UTF-8」「UTF-16」「Shift-JIS」「Unicode」などがよく使われると思います。とりあえずこの4つを試してみましょう。
まとめ
今回のまとめです。
- 文字化けの原因は文字コードが違うから。
- 文字コードは多言語対応させるために規格が乱立した。
- 文字化けしたときは違う文字コードで開き直してみる。
今回は以上です。

